一時間以上家を離れるとメールサーバがダウンする問題
自宅で運用されるメールサーバ
「WebとDNSとメールは自分で運用しなさい」「仕事で運用しているものを自宅で運用してはいけない」という教義に基づいて、我が家ではmacOSをサーバとしてWeb/DNS/メールを運用している。
このサーバにはMac Miniを使用しHeadless (ディスプレイを繋がない状態)で運用しているが、筐体が古くmacOSのサポート対象外となり、macportsの依存関係も壊れ始めていたため、Gmailのスパム対応強化の対応のためのメールサーバのDKIM導入を機に、重い腰を上げて新しく買って1年ほど放置していたM1 Mac Mini + macOS Sonomaに式年遷宮を試みた。
いくつかのトラブルはあったが、DNSとメールを新しいMac Miniに移行して、無事に運用を開始することができた。

いつのまにか無応答になっているメールサーバ
運用を開始していつかのタイミングからなぜかメールがセカンダリのサーバに届くようになってしまった。プライマリのMac Miniのメール関連のプロセスが死んだのかと思いトラブルシュートをしようとSSHを試みるも反応なし。pingにも応答なし。OSごとダウンしたと思い電源ボタン長押しで再起動をかけた。
何度かこの事象が発生しその都度ハードリブートをかけていたが、このままでは困るので時間を取って調査を開始した。
しかし system.log を見ても、mailのログを見ても、プロセスやOSがクラッシュした形跡はなく、何も分からなかった。
家を離れて1時間するとダウンするメールサーバ?
どのタイミングでセカンダリに切り替わったのかを調べることにした。これには何時のメールからセカンダリに届いたかを調べれば簡単にわかる。
直近は水曜日の17:30ごろ。この日は17:30から外部で講演の仕事があったため16:30に家を出た日。
その前は火曜日の9:00ごろ。この日は新しく着任されるチームメンバーを迎えるために8:00に出勤した日。
その前は…と調べていくと、どうやらPCを持って家を離れて1時間後にメールサーバがセカンダリに切り替わっているらしいことがわかった。そして30分程度で戻ってくる場合には切り替わりが起こっていないこともわかった。
どうやら一時間以上家を離れるとサーバがダウンしてしまうらしい。
………寂しくて死んでまうんか???
トラブルシュート開始
このMac MiniサーバはONUの位置関係上の制約でリビングでHeadlessモードで運用しており、ディスプレイを持ってきてつなぐのがちょっと面倒だったのでいままでハードウェアリブートする運用で対処をおこなっていたが、時間を取ってちゃんとトラブルシュートすることにした。
同様の事象が発生したタイミングでハードリブートは行わずにHDMIディスプレイを繋いでみた。画面は真っ暗。OSが落ちているのであれば期待通り。
次にキーボードとトラックパッドをBluetoothで接続してみた。すぐに反応はなかったが、トラックパッドを叩いていると画面が復活した。
……もしかしてSleepしていた…?
解決へ
SettingsでSleep周りの設定を確認したところ、Settings > Lock Screen の Turn display off when inactive が For 1 hour になっていた。これが1時間の原因。

つぎに Settings > Energy Saver を確認すると Prevent automatic sleeping when the display is off が disable になっていた(画像はenableしたあとのもの)

なんで家にいる間にこれが発動しなかったのかを振り返ってみると、家でPCを使っている間はMac MiniサーバにScreen Sharingで画面に接続していたからであった。
そのためPCを持たずに外出したときも問題は起こらなかったし、PCを持って外出しても1時間以内に帰ってきたときは、自動的にScreen Sharingが再接続をするので問題は起こらなかった。
PCを持って家を出て一時間経過したときだけ、自動的にディスプレイがオフになり、OSがスリープモードに入り、メールサーバがダウンしていたのだった。
わかってみればなんてことのない問題だった。
ちなみに古いMac MiniではEnergy SaverでSleepの設定をすべてNeverにしていた。

教訓
macOSでサーバを運用するときは Prevent automatic sleeping when the display is off を有効化しましょう。
ブコメ返し
LinuxともBSDとも勝手が違うし情報もそこまで多くないのでハードルは高いですねー(わかってくれる人がいて嬉しい)。
macOSで運用してるのも仕事で運用してないものを使う教義の一貫なのかな - sora_h のブックマーク / はてなブックマーク
Yesです。LinuxはRHELベースとDebianベースと両方やっているので、プライマリがmacOS、セカンダリがFreeBSDです。あとmacOSはTime Machineがあるのでバックアップがすごい楽なのが気に入ってます。
Webは自分で運用する教義でも、blogははてなでいいのでしょうか? - kazuau のブックマーク / はてなブックマーク
いい質問ですね。自分のサーバだと検索エンジンのSEO的に不利な点が多すぎる(&そこに頑張りたくなかった)のでブログについてははてなを利用しています。Webはプロフィールぐらいしか載ってません。
夜中おちなかったのかな? - GARAPON のブックマーク / はてなブックマーク
はい、PC(MacBook Pro)をScreen Sharing立ち上げたままつけっぱだったので落ちませんでした。
この手の新ネタを見るたび、「500マイル」と「バニラアイス」と「中国茶」のエピソードとしての強さが際立つ。 - six13 のブックマーク / はてなブックマーク
ほんまね。でもそんなおもろいやつそうそう起きひんって。
電気代かかるからやらない - mayumayu_nimolove のブックマーク / はてなブックマーク
すんません。M1になったのでちょっとマシになるはず…
KDDIの通話・通信障害メモ
この記事は7/3午前中に記載したもので、まだKDDI社長の会見内容を反映していません。
今回のKDDIの障害が具体的にどういうサービスに影響が出るのものか、モバイルネットワーク初心者としてLTE/EPC/IMS周りの挙動の勉強のためにまとめてみた。
はじめにまとめ
モバイルの通信には音声通話とデータ通信があり、今回主に長時間の障害を受けたのは音声通話(IMS)の方だった。
7/2(土)の日中帯はデータ通信はできるが音声通話やそれに付属するサービスが利用できない状態が継続していた。データ通信も不安定な状態になっていた。
端末の実装(主にAndroid端末)によっては音声通話ができないとデータ通信も止めてしまう挙動があった。これによりLTEを回線として使用しAndroidベースで構築された決済システムなどが利用不可能な状態が継続した。
音声通話(IMS)が利用できないと、通常の電話はもちろん、緊急通報、SMS、位置情報の送信などの機能が利用できなくなる。IMSに依存しているキッズ携帯の機能が全滅して防犯上の課題も生じていた。
サービスの状況
- 7/2未明の障害発生時は音声通話とデータ通信の両方ができなかった
- 7/2 7時ごろにデータ通信が一部回復
- 7/2 午前中には圏外表示を繰り返すようになり不安定
- 以降データ通信も時々不安定になる状態が
- auの携帯電話に通話すると「現在使われておりません」となる
au、データ通信が一時的にできるようになったけど
— ♥️電波やくざ様は告らせたい♥️ (@denpa893) 2022年7月1日
音声通話はできないままだな pic.twitter.com/KWRznDz89m
KDDI広報の携帯に電話したが現在使われておりませんってながれるw
— ♥️電波やくざ様は告らせたい♥️ (@denpa893) 2022年7月2日
端末による挙動の違い
音声通話は使用できないがデータ通信は可能なので外出時もLINE等は利用可能かと思われたが AndroidとiPhoneでIMS障害時のデータ通信の挙動が違うらしいことがわかった。
- iPhone
- アンテナピクトは立っていないがデータ通信は可能であった
- ハンドオーバーしたときに時々データ通信もできなくなることがあった(4G表示が消える)ので完璧に通信可能というわけではなかった模様
- アンテナピクトは立っていないがデータ通信は可能であった
- Android
- データカード
- データ通信専用なので通常通り利用可能であったようだ
auの通信障害は、
— す ぃ (@WGM_sui) 2022年7月2日
Androidかつ通話機能付き=全く疎通せず(通話が通じないと通信にチャレンジしないものと思われる)
iPhone=アンテナピクトは立たないが通信は可能
通話機能がない端末(タブレット・WiMAX等)=通常通り
私の手持ち端末全部で試した結果はこれ。
データは通るけどIMSへの登録ができてない時の挙動は端末依存ですね。
— A.N (@chunta8) 2022年7月3日
特にAndroidはメーカー&機種&ファームウェア依存なので、一概に言えないようです。
SIMフリーの機種も増えてきて全ては把握不可能に近そうです。
例えば、OPPOの場合は、
ピクト全立ち&データ通信可能&音声不可
でした。
3Gへのフォールバックができない
VoLTEのIMS障害なのでVoLTEをオフにすれば3Gにフォールバックして使用可能になるかと思われたが、KDDIは3月末に3Gのサービスを終了していたので3Gにフォールバックできなかった。
5G SAは一部の法人ユーザに提供開始していたが、コンシュマー向けにはこの夏提供開始予定だった。
そのため3Gにも5Gにも切り替えることができず、ユーザ端末側からはどうしようもなかった。
追記
障害箇所の推測
- 端末の挙動を見る限りIMS Registrationに失敗している模様
- P-CSCFから先のI-SCSF、S-CSCF、HSSあたりでなにかあったんじゃないかと思われる
- [追記] 7/2日中帯ではIMSにつながるPGWとのセッション確立失敗が見えていたとのこと
- これにより前述のIMS Registrationが失敗したり、データ通信も不安定になっていたのだと推測される
- この事象を解決するタイミングで輻輳が開始した模様
- KDDIからもVoLTEの交換機故障による輻輳とアナウンスがあったのでIMSの障害で確定
- おそらく何かをトリガーにしてUEが一斉にVoLTEのIMS Registrationを一斉に送り始めて、CSCF以降のIMSでコントロールプレーンの輻輳(キャパシティを上回る要求)が発生した可能性が高い
- 他社携帯から架電すると「現在使われておりません」となるので、単なるP-CSCFの輻輳ではなくHSSあたりまでR/W負荷が集中して加入者情報の一貫性の喪失のような異常が起こっているのではないかと思われる
- 全国的に影響が出ていることからもP-CSCFのようなフロントエンドの輻輳ではなくHSSのようなバックエンド側で異常が起きてるように思われる
IMSの確立NGのcauseはesm #26 Insufficient resources
— まがのり (@maganori) 2022年7月2日
でreject。朝からts24.301開いてしまった。
serevice requestもたまに反応ないな#KDDI #au pic.twitter.com/kSW8btuF0w
VoLTE交換機=IMSのことで、青丸の当たりです。
— かねがえ|セキュリティ勉強中 元電話研究員 (@nekokane) 2022年7月2日
輻輳するなら入り口のP-CSCFかな? pic.twitter.com/Lka86CPHBW
7/2の未明は分からないですが、日中帯以降はIMS Registration失敗やIMS障害ではなく、IMSに繋がるPGWとのセッションの確立失敗に見えておりました。
— まがのり (@maganori) 2022年7月3日
会見では、きっかけはPGWとIMSの間のルータ障害と言っていたので、そこを通らない様変更しPGWとのセッションを解放&再確立させたら輻輳したと思います
エンドユーザへの影響
IMSが落ちたときにエンドユーザに対してどのような形で影響が出たのかを整理してみる。社会的な影響はpiyokangoさんがまとめてくれているので、技術的観点から。
緊急通報
緊急通報の発呼フローの中にIMS Registrationが含まれているため、IMSに接続できなくなると110や119への緊急通報も発呼できなくなる。
実際に登山中に転落された方がauだったために通報できない事例が発生した。
夫婦が登山中に夫が転倒し下山できなくなったが、2人ともauの携帯電話を使用していたため通報できず(別の登山者が通報し防災ヘリで救助) pic.twitter.com/NadBYuIuvm
— suken@今年は夏の熱戦を4Kで見よう (@takakuratch) 2022年7月2日
緊急通報はTS23.167 あたりかしら pic.twitter.com/S7QJERYy33
— omusubi (@omusubi5g) 2022年7月2日
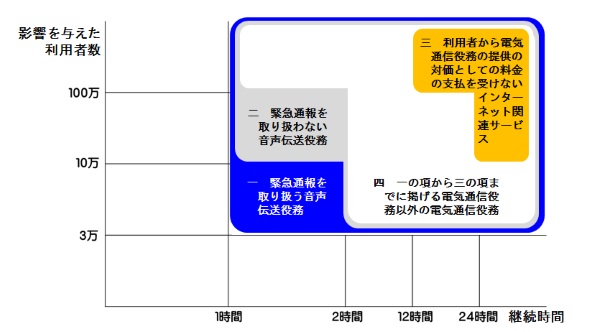
緊急通報を取り扱う音声伝送役務は1時間または3万人を超えたら総務省の障害報告基準に当たるので、一発アウトだったと思われる。
SMS
SMSにはSMS over IMSとSMS over SGsがあるが、KDDIの一般的なスマートフォンでサポートしているのはSMS over IMSであったため、SMSもほぼ利用不可能になっていたと思われる。
SMSが利用不可能になったことにより、SMSログインやSMSによる二要素認証などのSMSに依存したシステムが使用不能になる。特に自社の公衆Wi-Fiの認証に自社のSMSを使ってしまうとこのような障害のときに困ることがわかった。
- Yahoo!JapanのSMSログイン
- au Wi-Fi SPOTのSMSログイン
- Amazonの二要素認証
- クレジットカード会社や銀行のSMS認証
KDDIさんは普通のスマホはSMS over IMS onlyなのか。https://t.co/IhTB8LUsyt pic.twitter.com/fFFV7UNPWH
— かねがえ|セキュリティ勉強中 元電話研究員 (@nekokane) 2022年7月3日
LINEモバイルのau回線だけど、WiFiだから大丈夫だって思ってたら、YahooのログインでSMS使えなくて詰んだ\(˙◁˙)/
— 心奏〈かなで〉 (@Isolation_wolf) 2022年7月2日
通信障害中のkddiからauの公衆wifiをお使いくださいというお知らせを頂いた。使ってみた。そもそも公衆wifiのログインがSMS認証が必要なので、認証コードが届かなくて笑った。中の人、頑張ってください。おもしろすぎた。 pic.twitter.com/ozzG48tgZT
— むらかみふくゆき Fukuyuki (@fukuyuki) 2022年7月2日
au の通信障害のせいでSMS認証出来ねぇ
— じょー∞ (@Full_investdfx) 2022年7月2日
2要素認証にのこんな弱点があったとは…
au障害のせいでSMS受信できなくて、Amazonログイン出来なくなったw
— ゆん (@Yun_ValeforFF14) 2022年7月2日
セキュリティ重視の二要素認証だから仕方ないとはいえorz
au復活したー!!
— BB (@ryotkbb) 2022年7月2日
ネットも電話もSMSもだめで、クレカのSMS二要素認証できなくて詰んでた
2台持ちとか勘弁だから、複数の回線を切り替えられるスマホ出ないかな(SIM差し替えも嫌w)
位置情報
端末の位置情報もIMSで送信されるため、IMSによる位置情報の収集・利用ができなくなる。IMS経由の位置情報に依存しているシステムは後述するキッズ携帯がある。
一方でバスのロケーションシステムはGPSで得た情報をデータ通信で送信していることが多いため、IMSには関係がなく利用できるはずだが影響が出ていた。影響を受けたシステムはAndroidベースの端末になっていてIMS障害の影響でデータ通信もできていなかった可能性が高い。
神奈中バスロケーションの不具合についてhttps://t.co/AjghOjpr5N
— かなち - カナちゃん号HP (@kanachango) 2022年7月2日
KDDIの通信障害の影響により車両通信が安定せず一部不具合 pic.twitter.com/5CC4xNOtVz
ICカード決済やクレジットカード決済
バスなどの移動体や自動販売機や精算機でICカードやクレジットカードの決済ができなくなった模様。LTE回線を使用してデータ通信で実装されていることが多いので、これらのシステムはAndroidベースで実装されており、IMS障害にデータ通信も巻き込まれた可能性が高い。
au回線の不具合のため全ての乗客のバスのモバイル決済不要って🥺
— Kiyomi. (@felizdia92) 2022年7月2日
無料になってしまった💦 pic.twitter.com/QK6aJjnRpq
https://twitter.com/clouded19/status/1543428565143658497?s=20&t=0TT7M_kzIFMfxaBLg28-4g
au復旧したっぽいヽ(´▽`)/
— こにたん@4.14日本武道館 (@clouded19) 2022年7月3日
自販機でコーヒー買えたよ!
CokeOn使えないのはもしかして、自販機の中の通信auだったりするのかな。スマホのほうの決済はうまく行くけど
— ambasad (@ambasad) 2022年7月3日
タイムズ、au回線だったか、、、 pic.twitter.com/rDPzyVnyxP
— shao / 澤田 翔 - デジタルネイティブ企業のコーポレートIT支援 (@shao1555) 2022年7月3日
キッズ携帯
個人的にはこれが一番ヤバそう。キッズ携帯はデータ通信がなくてIMSのみを使用しているため機能が全滅する。
通話ができない、SMSが送れない、位置情報確認ができないことによって、防犯ブザーがなったときの自動通話や、写真・位置情報の送信ができなくなるなどの防犯機能がほぼ無効化されてしまう。
IMSが落ちている時は子供を一人で外出させないなどの対応が必要になりそうだが、子供が学校に行っているときなどの日中帯に障害が起きたときには防ぎようがない。
- 通話できない
- SMSできない
- 位置情報確認(安心ナビ)できない
- 防犯ブザー発動時の位置情報送信・SMS通知が機能しない
auの通信障害いつ治るの🙁?
— 8y🎀6y🎀1y🚗 (@M59165685) 2022年7月2日
子どものキッズ携帯防犯ブザーを引っ張ったら私に自動で電話がかかるんだけど、キッズ携帯の防犯ブザー引っ張ったら通信出来ませんって出たよ😇
緊急の時だったらと思うと本当困るし何のためのキッズ携帯なのってかんじ😇
きょうはauの電波障害で我が家はみんな電波障害。
— いしげまやこ (@stone_underson) 2022年7月2日
LINEで連絡は取れるけど、塾に行った息子と連絡が取れずちょっと困りました。
(息子はキッズ携帯だからLINE使えず)
我が家のリモコンも電池切れじゃないのに急に効かなくなるし、みんな暑くてやる気ないのかな。
南の島の人は働かないっていうし…^^;
auの通信障害、流石に酷い。自分は丸一日全く使えてない。そして息子のキッズケータイはau。今日もし仮に外出中に息子と連絡とったり位置情報確認したくなったりした際に障害が発生していたら…と思うと恐ろしい。キッズケータイはキャリア冗長が出来ないのも悩ましい。
— アザラシおっさん (@azarasyossan) 2022年7月2日
IMSがダウンしても大丈夫な機能
緊急地震速報
緊急地震速報はETWSなのでIMSがダウンしても大丈夫。 LTEなETWSではCBCからMME、eNB経由でUEに送信される。今回はMMEに障害はなかったのでセーフ。
現在、通信がしづらい状況についてお問い合わせを多く頂いており、窓口が大変込み合っております。
— au (@au_official) 2022年7月2日
ご迷惑をおかけし、大変申し訳ございません。
なお、緊急地震速報の受信については、影響ございません。
仕様・プロトコル
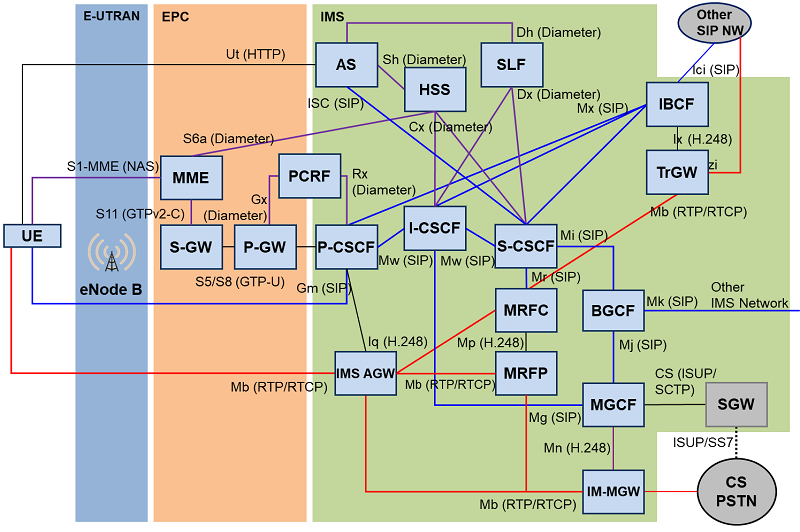
LTEのIMS
SIP/VoIP Security Audit | Solutions & Services | NextGen, Inc.
IMS Registration
IMS Registrationができなくて通話・通信ができないという話をしてきたが、この手順のフローは1ページに書けないぐらい長い。ざっくりのステップが以下の5つであるが、端末であるUEの他にP-CSCF、I-CSCF、S-CSCF、HSSという4つのプロバイダ側の設備(ネットワークファンクション)が連携して動作する。
どの設備がどこにどれだけの数配置されていて、どれだけの性能・キャパシティを持っていて、といったことを考え始めると今回の「輻輳」といったものに対処することがいかに難しいのかは想像しやすいと思う。
(1) GPRS Attach: The terminal registers to the GPRS Network.
(2) PDP Context Activation: An IP address is assigned to the terminal.
(3) Unauthenticated IMS Registration Attempt: The terminal attempts an IMS registration but is challenged by the IMS network to authenticate itself.
(4) IPSec Security Association Establishment: The terminal establishes a protected session with the IMS network.
(5) Authenticated IMS Registration: Registration is reattempted. This time the terminal is successfully authenticated and accepted.
以下の画像はIMS Registration Flowの4ページ中の2ページ目だけ抜粋したものである。

https://www.eventhelix.com/ims/registration/ims_registration.pdf
ETWS
LTEにおけるETWSではCBEが要求を出してCBCからMME、eNB経由でUEに送信される。このためIMSの障害の影響を受けない。一方的に情報を送るだけのシステムなので簡素化できている。

その他情報が分かり次第&勉強でき次第随時追記・加筆修正します。
https://twitter.com/omusubi5g/status/1543205131239321600?s=20&t=P05NemvKgsih4NdvWEWWww
https://twitter.com/maganori/status/1543022606659768320?s=20&t=P05NemvKgsih4NdvWEWWww
RFC8986 Segment Routing over IPv6 (SRv6) Network Programming
RFC8986 Segment Routing over IPv6 (SRv6) Network Programming
はじめに
この文書は RFC8986 Segment Routing over IPv6 (SRv6) Network Programming の翻訳です。
翻訳者はデータセンターネットワークの専門家ですが翻訳の専門家ではありません。技術的な意味を維持した上でなるべく読みやすい日本語になるようにしているため、英文の直訳ではなく一部のニュアンスがかけている場合がありますのでご了承ください。オリジナルの目次、謝辞、参考文献、RFC2119のやつ等は省略しています。
この文書はドラフトであるため、用語や表記が統一されていなかったり、仕様の内容について曖昧な部分がありますが、原文に忠実になるように訳しています。
免責
この翻訳を信用して不利益を被っても責任取れません的なやつ。
目次
- はじめに
- 免責
- 目次
- 概要
- 1. はじめに
- 2. 用語
- 3. SRv6 SID
- 3.1. SIDフォーマット
- 3.2. SRドメイン内でのSID割り振り
- 3.3. SID到達性
- 4. SR Endpoint Behavior
- 4.1. End: エンドポイント
- 4.1.1. Upper-Layerヘッダ
- 4.2. End.X: L3クロスコネクト
- 4.3. End.T: 特定のIPv6テーブルのルックアップ
- 4.4. End.DX6: カプセル化解除とIPv6クロスコネクト
- 4.5. End.DX4: カプセル化解除とIPv4クロスコネクト
- 4.6. End.DT6: カプセル化の解除と特定のIPv6テーブルのルックアップ
- 4.7. End.DT4: カプセル化の解除と特定のIPv4テーブルのルックアップ
- 4.7. End.DT46: カプセル化の解除と特定のIPテーブルのルックアップ
- 4.9. End.DX2: カプセル化解除とL2クロスコネクト
- 4.10. End.DX2V: カプセル化解除とVLAN L2テーブルルックアップ
- 4.11. End.DT2U: カプセル化解除とユニキャストMAC L2テーブルルックアップ
- 4.13. End.B6.Envaps: カプセル化を伴うSRv6 Policyに紐付けられたエンドポイント
- 4.16. Flavor
- 4.1. End: エンドポイント
- 5. SR Policy Headend Behavior
- 5.1. H.Encaps: SRポリシーにカプセル化されるSR Headend
- 5.2. H.Encaps.Red: Reduced Encapsulationを行うH.Encaps
- 5.3. H.Encaps.L2: 受信したL2フレームに適用するH.Encaps
- 5.4. H.Encaps.L2.Red: 受信したL2フレームに適用するH.Encaps.Red
- 6. カウンター
- 7. フローベースのハッシュ計算
- 8. コントロールプレーン
- 8.1. IGP
- 8.2. BGP-LS
- 8.3. BGP IP/VPN/EVPN
- 8.4. まとめ
- 9. セキュリティに関する考察
- 10. IANAに関する考察
- 11. 参考文献
RFC9136 IP Prefix Advertisement in Ethernet VPN (EVPN)
はじめに
この文書は RFC9136 IP Prefix Advertisement in Ethernet VPN (EVPN) の翻訳です。この文書ではEVPNのRoute Type 5 (IP Prefix)とサブネット間転送のための利用方法とユースケースの例が記述されています。
翻訳者はデータセンターネットワークの専門家ですが翻訳の専門家ではありません。技術的な意味を維持した上でなるべく読みやすい日本語になるようにしているため、英文の直訳ではなく一部のニュアンスがかけている場合がありますのでご了承ください。オリジナルの目次、謝辞、参考文献、RFC2119のやつ等は省略しています。
この文書はドラフトであるため、用語や表記が統一されていなかったり、仕様の内容について曖昧な部分がありますが、原文に忠実になるように訳しています。
免責
この翻訳を信用して不利益を被っても責任取れません的なやつ。
draft-ietf-bess-evpn-prefix-advertisement-11からの差分
基本的にはRFC化にあたっての参照先の最新化や用語の一貫性保持のための修正が行われているだけで、技術的な内容についての差分はありません。
- RFCの参照先の変更
- EVPN-INTERSUBNETがRFC9135に
- RFC5512がRFC9012に
- 表記の統一
目次
- はじめに
- 免責
- draft-ietf-bess-evpn-prefix-advertisement-11からの差分
- 目次
- Abstract
- 1. はじめに
- 1.1. 用語
- 2. 問題提起
- 2.1. データセンターにおけるサブネット間接属性の要件
- 2.2. EVPN IP Prefix経路の必要性
- 3. BGP EVPN IP Prefix経路
- 4. Overlay Indexのユースケース
- 5. セキュリティに関する考察
- 6. IANAに関する考察
ソフトバンク株式会社でモバイルネットワークで5GとかSRv6とかやっていきます

TL;DR
2021年10月1日からソフトバンク株式会社にITインフラアーキテクトとして入社し、モバイルコア向けのクラウド基盤をやっていきます。まずは得意分野の仮想基盤のネットワークを中心に活動して最終的にはソフトバンクのネットワーク全体に目を向けられるようになりたいなと思います。
これに伴いまして2021年9月末で新卒から10年半お世話になったNTTコミュニケーションズを退職いたしました。職場の皆様からは次のチャレンジを応援して温かく送り出していただきました。最高のチームでとても愛着のあるサービスでした。今までありがとうございました。
時間がない人のための一問一答
Q. なんで転職したの?
いきなり一言で答えられないので動機が強い順で書くと
- 80歳まで働かざるをえない世界に備えて5年後10年後を考えたキャリアパスを考えようと思った
- 前職でスペシャリストとして再就職したときにコミットしていたプロジェクトが一区切りついた
- 前職のチームもサービスも最高の状態で僕が辞めても大丈夫だと自信を持てた
次にやりたい技術があった - 今の環境がコンフォートゾーンに入っているなと感じた
- NTT以外の会社で働いてみたかった
- 転職を経験しておいたほうが良いと思った
- 居座り続けると後輩の成長機会を奪うことになると思った
Q. なんでモバイル?
こんなにたくさん使われているのに僕が理解してない通信インフラがあるなんてけしからんと思ったから
Q. なんで5G?
まわりがみんな5GCの話をしていてけまらしかったから
Q. なんでSRv6?
まわりがみんなSRv6の話をしていてけまらしかったから
Q. なんでソフトバンク?
- 超本気のラブコールをもらったから
- SRv6を商用導入していたから
- 元公社とは性質が正反対に見える「強い創業者の企業」で働いてみたかったから
「Japanese Traditional Big Company」といっても、強い創業者が率いる会社(トヨタ等)と、社長すら人事制度で定期的に交代する会社(NTT等)の2種類があるから気をつけるんだぞ。
— ゆやりん (@yuyarin) 2021年5月12日
Q. きっかけは?
友人のソフトウェアエンジニアが家を建てたので宅内ネットワークをローカル5GとSRv6にしようぜみたいな話をTwitterでやっていたら、ソフトバンクでSRv6と5Gに関わってるすごいエンジニアから「うちくる?」ってDMが飛んできたのでホイホイついていってしまった
Q. ITインフラアーキテクトってなにやんの?
モバイルテレコムクラウド基盤のアーキテクチャー策定と開発チームのリードをやるらしいけど、単にこの辺に応募してって言われて応募した職種のタイトルがこれだった感じです
Q. エンジニア?マネージャー?
部下なしのエンジニア(プロフェッショナル職)
Q. 給料あがった?
ベースの月収は下がってボーナス込みの年収の期待値は少し上がった感じ
Q. 他社は考えた?
3社から素敵なポジションにお誘いを頂いて3社とも内定を頂きました
Q. 他社のポジションは?
Q. 他社の待遇は?
前職と同等かそれ以上
Q. 他社と比べてソフトバンクの待遇が良かった?
一概には比較できないけどベースは前職より下がってるし一番高い他社と比べたらかなりの差があるのでそうでもない
Q. じゃあなんでソフトバンク?
モバイルができるのが魅力的で抗えなかった
Q. 他社よりキツくない?(大企業的な自由度とか総務省案件とか)
Q. キャリアパスだいじょうぶ?
わかんねー
Q. そんなに給料上げてどうすんの?(前職の上司から訊かれた質問)
上げてるのは自分の給与ではなくて日本のネットワークエンジニアの給与だったり日本国民の平均所得なんだと思ってる
Q. NTT退職エントリ?

いいえ、退職したかったわけじゃなくて転職したら退職することになっただけで今のチームには感謝しか無いので特に退職にフォーカスを当てる気はないですhttps://twitter.com/u1/status/1067712835508039680?s=20
Q. ドコモじゃだめだったの?
だめじゃなかった
Q. じゃあなんでドコモに行かなかったの?
もともとモバイルの仕事をやる前提で転職しようとしていたわけではなかったので、内定先の中からソフトバンクに決めてからドコモに打診をするとタイミング的に合わなくなるから
Q. なんでNTTグループを出たかったの?
僕が感じていたことをタイミングよくDeNAの南場さんがズバッと言ってくれていたので引用します:
入社してから30年以上ずっと同じ会社しか見ていない人たちが集まって改革だ、イノベーションだって議論しているわけですが、さすがに無理があるように感じてしまいます。
Q. 辞めると決めたときすっきりした?
むしろ最高の環境を捨てることがストレスになって盛大に肌荒れしたレベル
Q. NTTグループに戻ってくる可能性はある?
NTTコムであれば将来的に転職先の選択肢として十分に入るけどそのときにNTTコムが残ってるかはわからん
Q. 転職して後悔してない?
もう半年ぐらい遅らせておけばよかったなと思ってる…:
- 住宅財形を解約する前に家を買っておけばよかった(非課税で継続できるか確認中)
- ベース給与が下がる前に家を買って住宅ローンを組んでおけばよかった
- プライベートで有給休暇が必要そうなタイミングで転職しなければよかった
- 2年前の退職再就職時にお世話になった元上司の新しい職場でのミッションに貢献してから今のチームを離れればよかった
Q. 心残りは?
NTTグループ横断でエンジニアが集まってるSlackの在籍資格がなくなったこと
Q. 後任は?
前職の私のポジションの後任を募集していますので奮ってご応募ください(目安の値と違って実際は1000-1500ぐらい出ると思います)。
hrmos.co同じチームでエンジニアのポジションもありますのでこちらも是非ご応募ください(②がSDN寄りです)。
Q. 一緒に仕事したいんだけど?
この辺に応募してください!
さいごに
前職に向けてのメッセージ
Enterprise Cloud 2.0のSDNのチームに入って4年と2ヶ月でしたが、着任早々大障害が起きてその後もトラブルに見舞われ続けましたがなんとか安定させることができてSLAもいい感じの高い値を出すことができました。クラウドの開発チームはNTTコムの中では技術力的にもカルチャー的にもエンジニアにとって最高の環境で、僕のチームは最高のチームでした。あとはよろしくお願いします。ありがとうございました。また一緒に仕事しましょう。

現職に向けてのメッセージ
高く評価していただいて採用していただいてありがとうございました。今まで培ってきたインタードメインルーティングやデータセンターネットワーク・SDNなどのスキルと経験と成果を加味して将来性にベットしていただいたんじゃないかと思っていますので、皆様の期待に答えてリターンが出せるように精一杯頑張っていきたいと思います。これからよろしくお願いします!
IP Prefix Advertisement in EVPN (Draft 11)
はじめに
この文書は IP Prefix Advertisement in EVPN (ドラフト11版) (draft-ietf-bess-evpn-prefix-advertisement-11) の翻訳です。この文書ではEVPNのRoute Type 5 (IP Prefix)とサブネット間転送のための利用方法とユースケースの例が記述されています。
翻訳者はデータセンターネットワークの専門家ですが翻訳の専門家ではありません。技術的な意味を維持した上でなるべく読みやすい日本語になるようにしているため、英文の直訳ではなく一部のニュアンスがかけている場合がありますのでご了承ください。オリジナルの目次、謝辞、参考文献、RFC2119のやつ等は省略しています。
この文書はドラフトであるため、用語や表記が統一されていなかったり、仕様の内容について曖昧な部分がありますが、原文に忠実になるように訳しています。
免責
この翻訳を信用して不利益を被っても責任取れません的なやつ。
目次
- はじめに
- 免責
- 目次
- Abstract
- 1. はじめに
- 1.1 用語
- 2. 問題提起
- 2.1. データセンターにおけるサブネット間接属性の要件
- 2.2 EVPN IP Prefix経路の必要性
- 3. BGP EVPN IP Prefix経路
- 4. Overlay Indexのユースケース
- 5. セキュリティに関する考察
- 6. IANAに関する考察
QUICやHTTP/3で利用を避けるべき送信元ポートの議論についての考察

https://www.slideshare.net/yuyarin/quicnat
最近QUICとNATについての話をJANOGで紹介するぐらいQUICという新しいプロトコルに既存のネットワークインフラがどう適応していくかを考えています。
id:asnokaze さんの記事で紹介されているように、QUICやHTTP3/3で送信元UDPポートとして利用を避けるべきポートの議論が行われています。これはUDPのリフレクション攻撃のへの対応としてインフラストラクチャ側で特定のUDPポートのトラフィックをブロックしているケースがあるからです。実際に私もこのブロックの設定を行ったことがあります。 これはUDPというプロトコルの特性に起因する問題であり、QUIC, HTTP/3に限らずUDPを使うプロトコルに広くある問題です。
QUICクライアント側で送信元ポートとして利用を避けた場合でもインフラストラクチャ側のミドルボックスによって避けるべきポートを送信元ポートとして使用されてしまう可能性があります。一番大きな障害となるのがIPv4 Source NATでしょう
この記事ではHTTP/3を提供する場合についてのみ考察します。この記事でHTTP/3に対して問題ないと判断しても、QUICを使用する別のまだ見ぬ新しいアプリケーションレイヤープロトコルでは問題が生じるかもしれません。
結論
結論から述べるとHTTP/3でサービスを提供する事業者が制御可能な範囲内でこの問題を回避することができます。ただし世の中には例外があり100%ではありませんが、おおよそ問題になることはないでしょう。
IPv4 Source NATとUDP増幅問題
IPv4 Source NAT(以下SNAT)では一般のNATでもCGN/LSNでもwell-knownポートを送信元ポートには使用しませんので、問題になるポート番号は1024 - 65535の範囲でUDP増幅攻撃に使用されるポートです。これに該当するポートを増幅率の順で並べると次のようになります。
問題になりそうなポートをUDPの増幅率で並べ替えると次のとおりです。増幅率はA10さんの資料を参考にしました。
| ポート番号 | プロトコル | 増幅率 | 主な利用者 |
|---|---|---|---|
| 11211 | memcached | 10,000-51,000 | コンテンツプロバイダ |
| 27910 | Quake 2 | 63.9 | Eyeball/クラウド |
| 1900 | SSDP | 30.8 | Eyeball |
| 1433 | MSQL | 25 | エンタープライズ/クラウド |
| 4672 | Kad | 16.3 | Eyeball |
| 27000-27030 | Steam Protocol | 5.5 | Eyeball/コンテンツプロバイダ/クラウド |
| 1024-65534 | BitTorrent | 3.8 | Eyeball |
| 5353 | mDNS | 2-10 | Eyeball |
本来であれば増幅率の他にプロトコルの普及率などで考える必要があります。個人的な感覚では危ないのは次の3つかなと思います。これはMLの元のリストのうちwell-knownポートのプロトコル以外のものと一致します。
| ポート番号 | プロトコル | 増幅率 | 主な利用者 |
|---|---|---|---|
| 11211 | memcached | 10,000-51,000 | コンテンツプロバイダ |
| 1900 | SSDP | 30.8 | Eyeball |
| 5353 | mDNS | 2-10 | Eyeball |
memcachedはオンメモリのKey-Valueデータベースで主にコンテンツプロバイダなどのサービス提供側で使用されることが多いソフトウェアでありプロトコルです。UDP増幅攻撃においては非常に大きな増幅率を誇っており、一時期大きな問題になりました。
SSDPはUPnP(Universal Plug and Play)で使用されるプロトコルです。UPnPに対応している機器は家庭用ブロードバンドルータやプリンタなど主にEyeball側で利用される機器が多く、ターゲットもEyeball側になることが多いです。
mDNSは元々ローカルで提供されるサービスですが、一部の実装が外部からの問い合わせに応答してしまうことでUDP増幅攻撃に利用されています。
SNATで送信元ポートとしてこれらのポートを使うかどうか
結論から言うと使われる可能性があります。仕様として明確に禁止しているものがないため、実装や運用に依存します。
一般的なブロードバンドルータではそもそもSNATのエントリー数が数千と小さいため、エフェメラルポートの範囲で十分ですが、SOHO・中規模用のルータなどではSNATのポート範囲を1024まで拡張している場合があります。特定のポート番号についてそのポート番号を使用しないようにしている実装は稀だと思います(個人の感想)。
一番問題になるのがIPoEでのCGN/LSNの実装方式であるMAP-EなどのIPv6アドレスをIPv4アドレスとポート番号のレンジに静的にマッピングするタイプのSNATです。Subscriberあたり256個や512個のポート番号を連続した領域として割り当てるため、個別のポート番号だけを抜き取る実装はありません。そのポート番号を含むレンジをまるごと使用不可にすることは考えられますが、私の知る限りそのような実装はありません。
以降でこれらのポート番号が送信元ポート番号として使われたとしてもおそらく問題がないであろう(大きな問題にならないであろう)理由を述べます。
Eyeball側をターゲットとしたUDP増幅攻撃への対処

SSDPやmDNSはEyeball側の機器が増幅器になります。この攻撃を防ぐ箇所としては以下の8箇所が考えられます。これらのうち実際にブロックを行う可能性があるのは③か⑧です。
| 番号 | 場所 | 条件 | ブロックするか |
|---|---|---|---|
| ① | ISPのIngress全般 | 送信元ポート | しない |
| ② | ISPからSubscriberへのEgress | 送信元ポート | しない |
| ③ | SubscriverのIngress | 送信元ポート | しているかもしれない |
| ④ | SubscriverのEgress | 宛先ポート | しない |
| ⑤ | ISPのSubscriberからのIngress | 宛先ポート | しない |
| ⑥ | ISPのEgress | 宛先ポート | しない |
| ⑦ | ISPのSubscriberや顧客や子ASへのEgress | 宛先ポート | しない |
| ⑧ | Subscriberや顧客や子ASのIngress | 宛先ポート | しているかもしれない |
| ⑨ | Subscriberや顧客や子ASのIngress | 宛先ポート | しているかもしれない |
③のケースではSubscriberのCPEにおいて送信元ポート番号をブロックするケースですが、設定している可能性はそれほど高くなく、また、設定していたとしてもSNATのinside側で行われているかと思うので、無害でしょう。
⑧のケースでは宛先ポートですのでブロッキングを行っていたとしてもQUICには影響がありません。
③と⑧以外の箇所では「しない」としていますが、ISPによってはブロッキングしている箇所がある可能性があります。基本的にポート番号によるブロッキングは通信の秘密を侵害することになります。OP25Bのように正当業務行為による違法性阻却事由が成り立つ場合は、これを根拠に実施しているISPはありえます。ここはどの程度のISPが実施しているかを調査する必要がありますが、それほど多くはないかと思います。
HTTP/3でサービスを提供する事業者になりえるのは⑧、クライアント側になりえるのが③や⑧と考えたときに、上記のことからEyeball側がターゲットになるSSDPやmDNSについては、QUICの送信元ポート番号がこれらのUDP増幅攻撃対策のためのブロッキングから影響を受ける可能性は低いと思います。
コンテンツプロバイダ側をターゲットにしたUDP増幅攻撃への対応

memcachedはコンテンツプロバイダ側の機器が増幅器になります。この攻撃を防ぐ箇所としては以下の8箇所が考えられます。これらのうち実際にブロックを行う可能性があるのは③と④と⑧と⑪です。
| 番号 | 場所 | 条件 | ブロックするか |
|---|---|---|---|
| ① | ISPのIngress全般 | 送信元ポート | しない |
| ② | ISPから法人顧客や子ASであるコンテンツプロバイダへのEgress | 送信元ポート | しない |
| ③ | コンテンツプロバイダのIngress | 送信元ポート | しているかもしれない |
| ④ | コンテンツプロバイダのEgress | 宛先ポート | しているかもしれない |
| ⑤ | ISPの法人顧客や子ASであるコンテンツプロバイダからのIngress | 宛先ポート | しない |
| ⑥ | ISPのEgress | 宛先ポート | しない |
| ⑦ | ISPのSubscriberや顧客や子ASへのEgress | 宛先ポート | しない |
| ⑧ | Subscriberや顧客や子ASのIngress | 宛先ポート | しているかもしれない |
| ⑨ | Subscriberや顧客や子ASのIngress | 宛先ポート | しているかもしれない |
| ⑩ | ISPのSubscriberからのIgress | 送信元ポート | しない |
| ⑪ | ISPのSubscriberのIgress | 送信元ポート | しているかもしれない |
ISPでは基本的には法人顧客や子ASに対してトラフィックのブロッキングは行いません。
③も④もブロッキングを行っている可能性がありますがネットワーク外部の(例えばクラウドサービス上に立てた)memcachedにアクセスするためには必要なのでブロッキングしている可能性は低いです。③がクライアントからのHTTP/3のトラフィックに関係しますが、これはHTTP/3でサービスを提供する事業者側で制御可能な範囲なので対処可能です。
⑧はブロッキングしている可能性が高いです。これはmemcachedがUDP増幅攻撃に使用された場合の対処方法として、ネットワーク内部にmemcachedを立てている場合に信頼できるIPアドレス以外の外部からの宛先ポートが11211であるパケットを落とします。これはブロッキングを行っていてもHTTP/3には影響しません。
⑪はブロッキングされている可能性があります。これはEyeball側で内部でmemcachedがNW管理者の関知しない範囲で立てられていたときにUDP増幅攻撃に加担しないようにNW管理者側でブロックしているケースです。ただしこの場合もブロックはSNATを行う前に実施されるので、HTTP/3トラフィックに対する影響はありません。
HTTP/3でサービスを提供する事業者になりえるのは③、④、⑧ですが、いずれも影響がありません。
HTTP/3でサービスを提供するコンテンツプロバイダ側でできる対策
HTTP/3でサービスを提供しようとした場合に、UDP増幅攻撃の対処としてのブロッキングに影響を受けないためには以下の対応を行えば十分だと考えられます。
- SNATされないケースを考えて、HTTP/3クライアント側で送信元ポート番号に増幅攻撃に利用されるポート番号を使用しない(現在のWGの方向)
- 送信元ポート番号が11211であるトラフィックをブロックしているネットワークにHTTP/3のフロントエンドを設置しない(コンテンツ事業者の努力)
- SNATが行われなくても済むようにIPv6でのサービスを提供する(コンテンツ事業者の努力)
というわけで今のWGの流れは方向性としては概ね正しいかと思います。
もう少し踏み込んで少しの可能性も潰したい場合、memcachedの11211のブロッキングを回避するためには、送信元ポート番号として偶数番号を使うことが対策になりえます。なぜならRFC4787にもあるように多くのSNATの実装ではPort Parityとして送信元ポート番号の偶奇を保つようにしているからです。ただし送信元ポート番号の枯渇が2倍速になる問題があります。
最後に
これらはあくまでコンテンツとEyeballと単純に分割して考察した場合です。コンテンツプロバイダやクラウドサービス同士でHTTP/3でAPI提供が行われた場合なども考察する必要があります。
いずれにせよ、新しいプロトコルの発展を阻害しないためにみんなで協力しあって頑張っていきたいところです。
考慮が足りない箇所があったら遠慮なくコメント欄か @yuyarin までお知らせください。